【SQLServer】整理10种分布式id生成方案
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
在复杂分布式系统中,如金融、支付、订单等业务数据日渐增长而必须要采用对数据分库分表操作,此时就需要有一个唯一ID来标识一条数据或消息。下面介绍几种常见的分布式id生成方案。 1、UUID 代码实现如下所示:
2、数据自增主键
当需要唯一的id的时候,向数据库中添加一条数据并返回主键id,可以保证在当前的系统的中id的唯一性。
数据自增主键方案适用于小规模的、无高并发场景业务场景。 3、数据库集群模式 基于数据自增id主键方案存在单点问题,那么对其做高可用的优化,即就是使用数据库的集群模式来生成唯一id。
通过增加多台数据库服务并且给每个数据库都设置起始值,然后通过设置步长来让数据生成的ID趋势递增且不重复。
此方案适用于数据量不大,数据库不需要扩容的场景。 4、数据库号段模式 此方案实质就是批量从数据库获取自增的id,即就是每次从数据库取出一个号段范围,如(1-3000]表示从数据库中生成3000个自增id。数据表的设计如下:
业务申请号段的流程如下:
当一批号段用完之后,再次向数据库申请新的号段,此方案的的优缺点如下表所示:
5、Redis实现分布式id
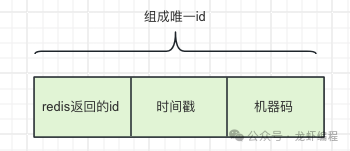
Redis提供的incr自增命令是单线程的操作,可以保证生成的id的唯一并有序的,我们联合如时间戳值、机器标识组成一个具有特殊含义的唯一id,如下图所示:
Redis生成唯一id的优缺点如下所示:
6、Zookeeper实现分布式id Zookeeper客户端创建顺序节点时会根据创建的时间顺序,在节点名称后添加 10 位的顺序编号,利用Zookeeper的这个特性实现id的唯一性。
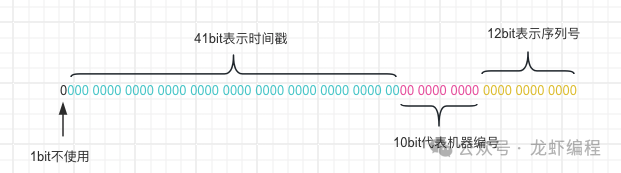
由于依赖Zookeeper并且存在多步的异步调用,如果竞争较大的的情况下还需要考虑使用分布式锁,因为很少会使用Zookeeper来生成唯一id。 7、雪花算法 雪花算法是使用一个64bit的long类型数字作为全局唯一id,下图是展示了雪花算法生成唯一id时候各个bit位的作用:
假设当前时间是2024-06-10 10:00:00,生成id的机器编号是7,序列号为1,据此雪花算法生成的id如下所示:
转为十进制如下:
虽然这样就可以生成一个唯一的id,但是雪花算法有如下的问题: (1)雪花算法严重的依赖时钟,如果出现时钟回拨就会导致重复生成id;解决时钟回拨的一种方式就是将代表机器码的十位拆出三位出来表示时钟序列,如下图:
当发生时钟回拨的时候,此时时间已经发生了变化,那么这时将时钟序列新增1位,重新定义整个雪花Id;为了避免实例重启引起时间序列丢失,时钟序列最好通过数据库或者缓存等方式存储起来。 (2)41bit最大的时间跨度是69年,后面会发生41比特位不够使用;解决方案是生成时间戳之后减去系统上线时候的时间。 8、百度uid-generator uid-generator是基于雪花算法实现的,uid-generator不同点在于它支持自定义时间戳、机器id和序列号等个部分的信息,其组成部分如下所示:
uid-generator的项目地址:
uid-generator具有高性能、去中心化、强一致性和易用性等特点而广泛的应用与生成数据库主键、订单编号和消息追踪等场合下。 9、美团的Leaf 美团的Leaf同时兼具了数据库号段模式和雪花算法,它可以试下可以根据不同业务场景灵活切换。 Leaf项目Github地址:
美团的Leaf详细两种模式介绍文档:
我们根据实际的业务特性来选择合适的ID生成方式。 10、滴滴的Tinyid Tinyid是在美团的ID生成算法Leaf的基础上扩展而来,是基于数据库的号段模式实现的,支持数据库多主节点模式。如下图如下所示:
项目的地址:
Tinyid提供了REST API和Java客户端两种获取方式,相对来说使用更方便,目前在滴滴客服部门使用,且通过tinyid-client方式接入,每天生成的是亿级别的id。性能上还是很高的。 总结: (1)分布式id生成方式有很多种方案,我们需要依据实际的业务场景来选择合适的方案。 该文章在 2024/7/22 9:00:26 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886