纯c#运行开源本地大模型Mixtral-8x7B
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
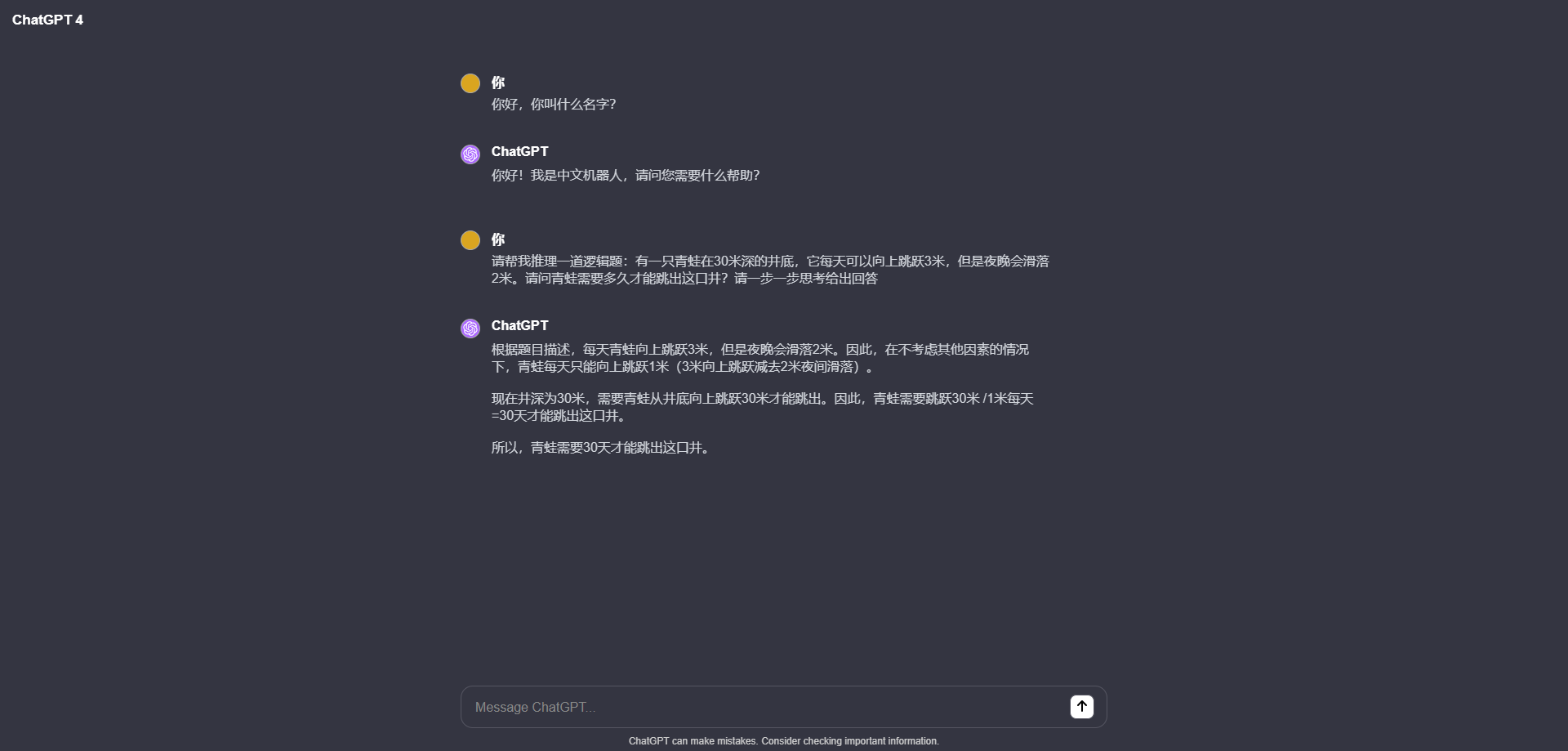
先看效果图,这是一个比较典型的逻辑推理问题,以下是本地运行的模型和openai gpt3.5的推理对比 本地运行Mixtral-8x7B大模型:
chatgpt3.5的回答:
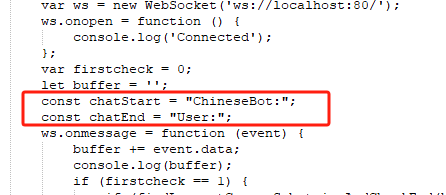
关于Mixtral 8x7B这个就不多介绍了,但凡在关注开源大模型的朋友应该知道这个模型是目前市场上最具竞争力的开源大型模型之一,其能力水平在多项任务中都有可以和gpt3.5打的有来有回,今天主要聊聊使用c#如何本地化部署实践 整个模型部署其实相对已经比较简单了,其核心是采用了llama.cpp这个项目,这个项目是用 ggml(一个用 c++ 开发的一个机器学习的张量库)写的一个推理 LLaMA 的 demo,随着项目持续火爆吸引了大量没有昂贵GPU 的玩家,成为了在消费级硬件上玩大模型的首选。而今天我们要用到的项目就是依赖llama.cpp的c#封装实现的nuget包LLamaSharp,地址(https://github.com/SciSharp/LLamaSharp)。基于它对llama.cpp的c#封装从而完成本机纯c#部署大模型的实现。通过LLamaSharp既可以使用cpu进行推理,如果你有30系以上的N卡,也可以使用它的LLamaSharp.Backend.Cuda11或者Cuda12进行推理,当然其效果肯定相比纯CPU推理速度更快。 整个项目我已经放到github上了,有兴趣的同学可以自取:https://github.com/sd797994/LocalChatForLlama 另外关于模型格式说一下,当前使用llama.cpp主要通过gguf格式加载,这是一种专门面向llama.cpp的格式,可以通过huggingface搜索:https://huggingface.co/models?search=gguf。而我目前使用的是Nous-Hermes基于Mixtral-8x7B微调的版本,它的repo如下:https://huggingface.co/TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF/tree/main 据说Nous-Hermes微调版本的性能略好于Mixtral-8x7B。唯一需要注意的是如果不是使用我推荐的模型,index.cshtml这里需要根据模型的实际输出硬编码成对应的字段:
最后的Tips:由于模型确实比较大,在纯CPU模式下如果内存不太够(一般16G)的情况下推理很缓慢,一分钟可能也就能输出几个字。建议上较大内存的纯CPU推理或者使用NVIDIA的显卡安装对应的CUDA环境后基于CUDA推理,整个效果会快很多。 作者:a1010 转自:https://www.cnblogs.com/gmmy/p/17989497 该文章在 2024/1/27 17:49:29 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886