聊聊SQL优化的几个小技巧
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
sql优化是一个大家都比较关注的热门话题,无论你在面试,还是工作中,都很有可能会遇到。 那么,如何优化Sql呢?本章节分享了12个小技巧,我们一起来学习下。
1、避免使用select * 查询很多时候,为了使用起来方便简单,我们喜欢直接使用select * 来查询数据。 反例:
但实际开发过程中,我们可能并不需要返回所有的字段列,而是其中的某几列,这个时候建议大家直接列出查询字段。 正例:
使用select * 的弊端:
2、使用union all替换unionunion:union操作符会合并两个查询结果集,并去除重复的行,只保留一个副本。
union all:union all 不去除重复行,直接将两个查询结果集合并在一起。
从性能层面分析:
在实际使用过程中,我们还是要视情况而定,比如说我们就是需要去重复的行数据,则需要使用union。 3、避免使用子查询如果我们想要从两张或者多张表中查询到数据,通常的实现方式:连接查询或者子查询。 子查询的例子如下:
网上查询有关不建议使用子查询的缘由是:需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。 建议调整为连接查询:
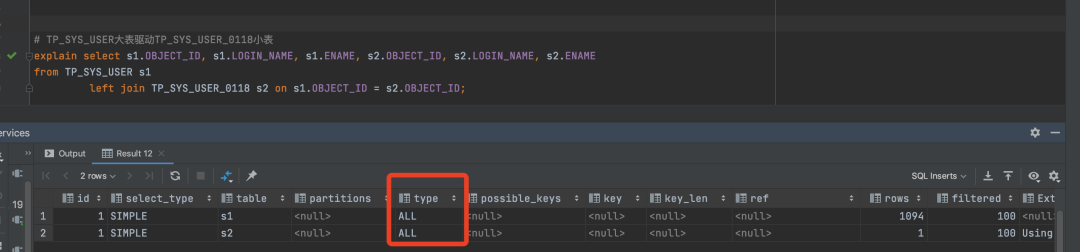
4、多表查询时一定要以小驱大例如我们使用left join 连表查询: 场景一:以大表驱动小表
通过explain分析SQL的执行计划:
我们发现两个表的type都是ALL:表示全表分析,然后才找到匹配的行,我们可以通过字段rows看到查询的行数据。 场景二:以小表驱动大表
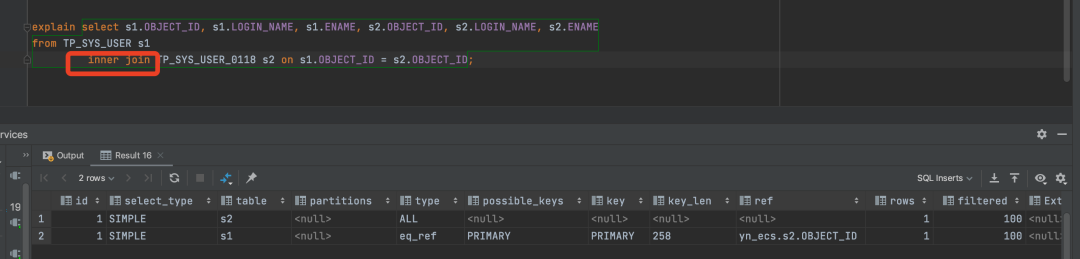
通过explain分析SQL的执行计划:
我们可以看到s2表的type是eq_ref:表示查询时命中主键 primary key 或者 unique key 索引,这里使用的是primary key。并且查询rows的行数是1 通过explain分析我们可以很明显的对比出来,用小表驱动大表的时候,查询效率更高些。 或者我们也可以使用inner join 来替换left join的以小表驱动大表的方案。
5、不要使用like左模糊和全模糊查询场景一:使用like右模糊查询
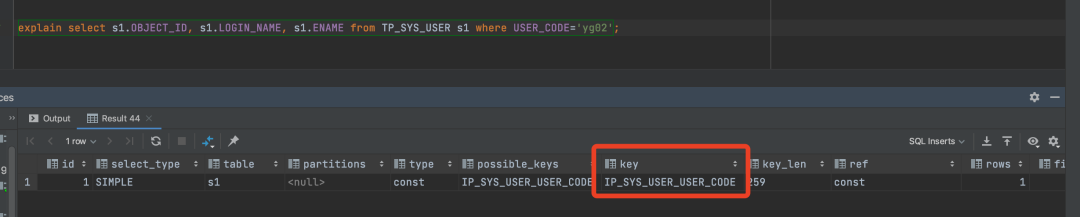
通过explain分析SQL的执行计划:
我们可以看到key(实际使用的索引)是有值的: 执行结果中key有值:表示查询中实际使用的索引为IP_SYS_USER_USER_CODE。 场景二:使用like左模糊查询
通过explain分析SQL的执行计划:
执行结果中key为null表示没有使用索引查询。 场景三:使用like全模糊查询
通过explain分析SQL的执行计划:
执行结果中key为null表示没有使用索引查询。 通过以上几种场景对比,我们可以看到like左模糊查询和全模糊查询都是没有走索引的,所以查询效率较低,我们不建议这么使用。 6、exists&in的合理利用exists&in一般用于子查询。
7、在表中增加索引,优先考虑where和order by使用到的字段通过为字段添加索引,来提升查询效率,例如:
8、避免在索引上使用内置函数反例:
正例:
使用内置函数会导致索引失效。 9、!=、<>、not in、not like、or...要慎用例如如下几种场景:已知USER_CODE存在索引
通过explain执行计划分析,共通之处是key为null,表示没有走索引,也就意味着存在的索引USER_CODE并没有发挥作用,索引失效。 10、提升group by的效率在实际业务,我们经常性的会用到group by 来分组获取数据,不知道小伙伴是否有这样的习惯:先group by 然后在通过having过滤条件。 反例:
分组是一个消耗性能的动作,我们为什么不先加过滤条件,缩小范围数据范围在分组呢? 正例:
使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。 11、明确仅返回一条数据的语句可以使用limit 1在业务开发过程中,我们有没有遇到过这样的场景,按照时间排序,我们只需要获取最新的数据。 例如:
在业务逻辑中,我们可能通过代码逻辑底层使用如上SQL获取到的数据集合,然后在通过collection.get(0),获取到第一条数据。 虽然这种做法没啥问题,但是它的效率很低,怎么优化呢?
如果我们很明确我们的业务需求,就是获取最新的数据,我们可以直接在排序后加上limit 1,表示只获取结果的最新1条。 12、业务逻辑尽量批量化完成如果存在业务需求,我们需要插一批数据入库。 场景一:执行单次插入操作:
执行SQL:
这个过程是在for循环中执行的,我们需要多次的请求数据执行插入操作。 场景二:执行批量插入操作:
执行SQL:
这个过程,我们可以一次完成,不需要多次请求数据库。相比较场景一的多次请求,相对而言我们批量插入的操作会大大提升客户端的请求性能。 如果批量插入的数据量过大,我们也建议分开执行,比如200条一次。 该文章在 2024/1/22 8:58:35 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886