SQL优化方法论与实战
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
正文首先为什么要进行优化?说得直白点,无外乎是为了在现有资源情况下,不付出额外的成本,提升体验,又曰——降本增效。
那么数据库作为日常背锅选手,有哪些可以衡量性能的指标呢?我大致列了以下几项:
比如应用告警报错阈值是 10 ms,如果某个时间段报错数量急剧增加,这个时候可能数据库的状态就不太正常了,其次数据库的缓存命中率其实也可以从侧面反映出数据库的状态,大量 cache miss,性能注定好不到哪里去。
而延迟作为集中式数据库的关键性黄金指标,延迟至关重要,假如我在某个商品界面上发起下单请求,等了许久才弹出一个付款界面,那么我会转身就走,购买欲望瞬间降至冰点,延迟直接关系到用户体验。 那么作为 DBA 的我们,对于延迟也要有个大概的"尺度",比如稍微差一点的盘,寻道时间在 3 ~ 10 ms 左右,毫秒级别,L1 / L2 CPU 缓存则在纳秒级别,内存访问的话则是在 100 纳秒的级别。那如果现在有个 redis ,延迟为 100 ms,你说慢不慢?当然是慢的抠脚。
烂 SQL 的危害如果真要一一列举出来,可能到天黑都说不完,烂 SQL 往往是导致数据库性能衰减的元凶,性能问题源于 SQL,之外可能源于并发 (居多) 或数据库和操作系统自身维护性操作 (vacuum / freeze) 等等。
因此获取现场就变得尤为重要,但 PostgreSQL 一直恼于没有原生好用成熟的 AWR 工具,所以得借助一些第三方工具,此处我也简单整理了一下常用工具和插件,比如类似于 cursor sharing 的 pg_shared_plans,执行计划固化 sr_plan / pg_plan_guarentee 等,pg_stat_statements 肯定得装上,基于 pg_stat_statements 实现丐版 AWR 也可以,关于这点可以抄作业 👉🏻 Using pg_stat_statements to Optimize Queries
SQL 从客户端发起,到数据库执行,再到接收,中间的每一环节都至关重要,比如网络带宽直接就决定了数据库的吞吐量,这里要提一句的是,和 fetchsize 类似的是 FETCH_COUNT,也是为了防止客户端 OOM,当客户端向数据库发送请求时,如果结果集很大,可能会把客户端的内存打爆,悠着点儿。
SQL 的逻辑顺序不多说了,关于物理执行顺序需要说明一下。 当一条查询进来之后,会经过Parser → Analyzer → Rewriter → Planner → executor 这一系列步骤,生成各种各样的"树"。若是 DDL 语句,无需进行优化,到 utility 模块处理,对于 DML 则需要按照完整的流程。(最近我正在看 "Journey of a DML query",后续也会分享给各位)。 对于数据库来说,传入的 SQL 语句不过是一串"文本",PostgreSQL 并不知晓也不理解这一串文本是什么意思,因此我们需要告诉数据库该如何理解这一串文本,之后 SQL 语句就会被转化为内部结构,即语法解析树,再经过优化的处理,最终转化为执行器可以高效执行的计划树。 而优化器作为数据库的大脑,优化器的好坏直接决定了一个数据库的"上限",决定了一个数据库面对复杂语句的处理能力。说白了,逻辑优化就是尽量对查询进行等价或者推倒变换,以达到更有效率的执行计划。因为 SQL 是声明式语言,我们只是指定了需要返回什么结果,而没有指定它该怎么做。 在此也贴一个关于优化器涉及到的相关参数和系统表,以及核心代码流程,之前有位读者问过我这块:
对于 Greenplum 来说,他既支持传统 PostgreSQL 优化器,也有 ORCA。对于 GPORCA 不支持的特性,GPORCA 会自动回到 Planner。
其中 PostgreSQL 优化器采用了两种方法:自底向上使用的是动态规划,随机方法使用的是遗传算法,由geqo_threshold 参数控制何时使用遗传算法,默认是 12。 对于 OUTER JOIN 来说,JOIN 顺序是固定的,所以路径数量相对较少 (只需要考虑不同 JOIN 算法组成的路径);然而对于 INNER JOIN 来说,表之间的 JOIN 顺序是可以不同的,这样就可以由不同的 JOIN 组合、不同的 JOIN 顺序组成非常多的不同路径。如
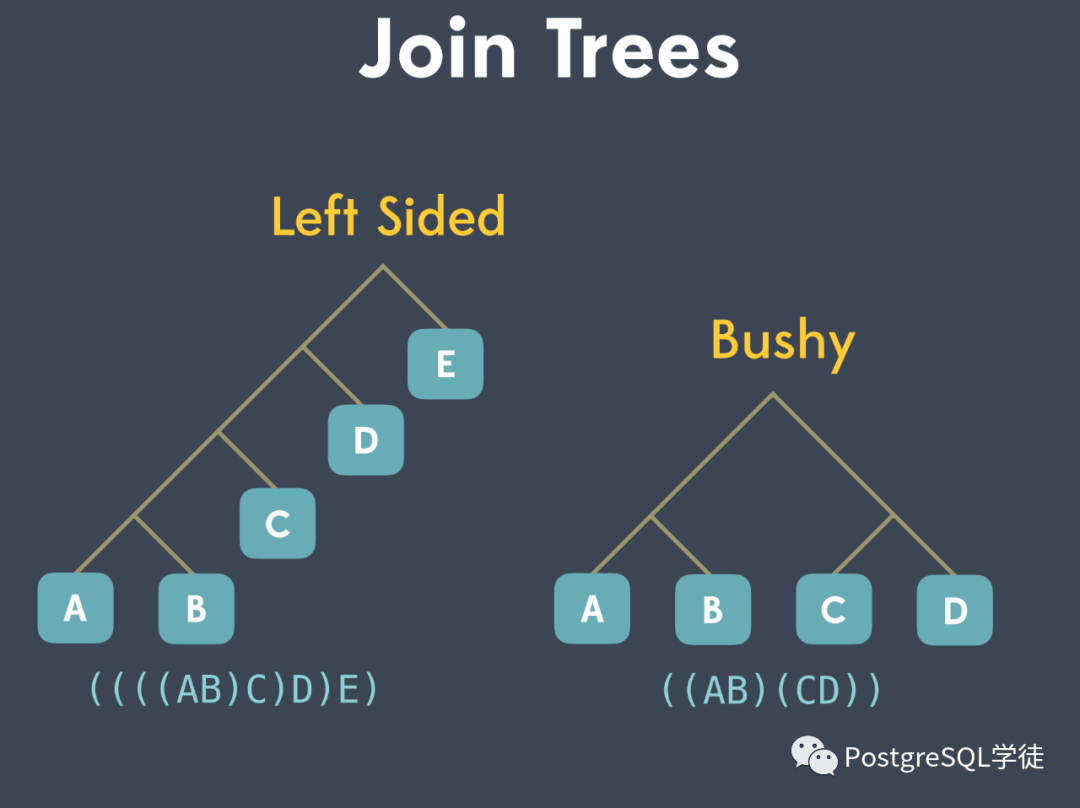
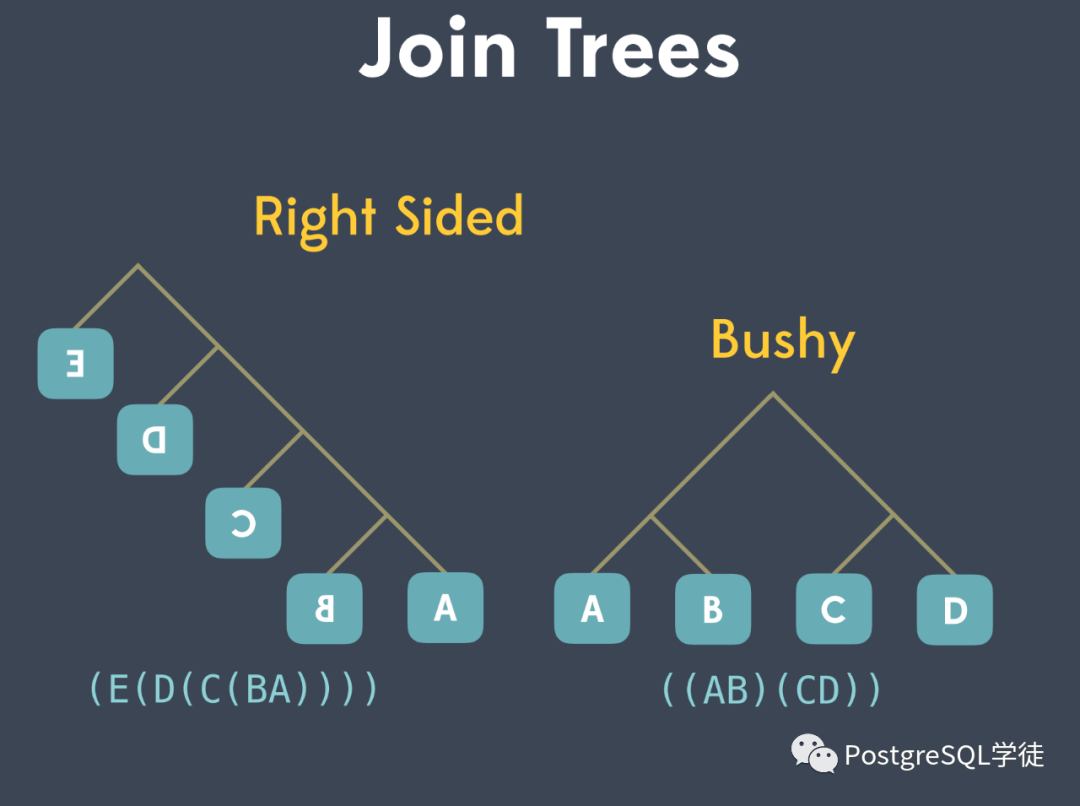
等等。多表间的连接顺序表示了查询计划树的基本形态。一棵树就是一种查询路径,SQL 的语义可以由多棵这样的树表达,从中选择花费最少的树,就是最优查询计划形成的过程。一棵树包括左深连接树、右深连接树、紧密树。PostgreSQL 优化器主要考虑将执行计划树生成以下三种形式,包括左深树、右深树和紧密型树。不同的连接顺序,会生成不同大小的中间关系,对应 CPU 和 IO 消耗不同。 PostgreSQL 中会尝试多种连接方式存放到 "path" 上,以找出花费最小的路径。
试想一下,如果A ⨝ B ⨝ C ⨝ D,那么有 N! ✕ (N-1)! 这么多种可能的计划 (ABCD, ABDC, ADBC, DABC ...)。人们针对树的形成及其花费代价最少的,提出了诸多算法。树形成过程有以下两种策略:
在数据库实现中,多数数据库采取了自底向上的策略。就 PostgreSQL 而言,查询优化可以大体分为四个步骤:
如果看到这样类似的关键字,则代表是 ORCA 优化器,其是基于自顶向下的查询优化器,对于复杂 SQL 性能较好,但是生成执行计划的时间也更久。
让我们看一个实际的例子 (Greenplum 相较于 PostgreSQL 多了一些算子和术语) :
这里主要提一下 rows 的预估,各位可以参照我之前写的执行计划篇章,根据 pg_stats 统计信息计算而来,这也再次说明了统计信息的重要性,不然优化器无从下手。
当然还有各种各样的辅助算子,用于执行某些特定操作,比如
扫描方式就不多说了,顺序扫描 / 索引扫描 / bitmap scan,不过 Greenplum 是支持 bitmap 索引的。
对于向量化计算,各位可能也经常在各大产品 PR 里面听到,此处推荐阅读一下 PgSQL · 引擎介绍 · 向量化执行引擎简介 “
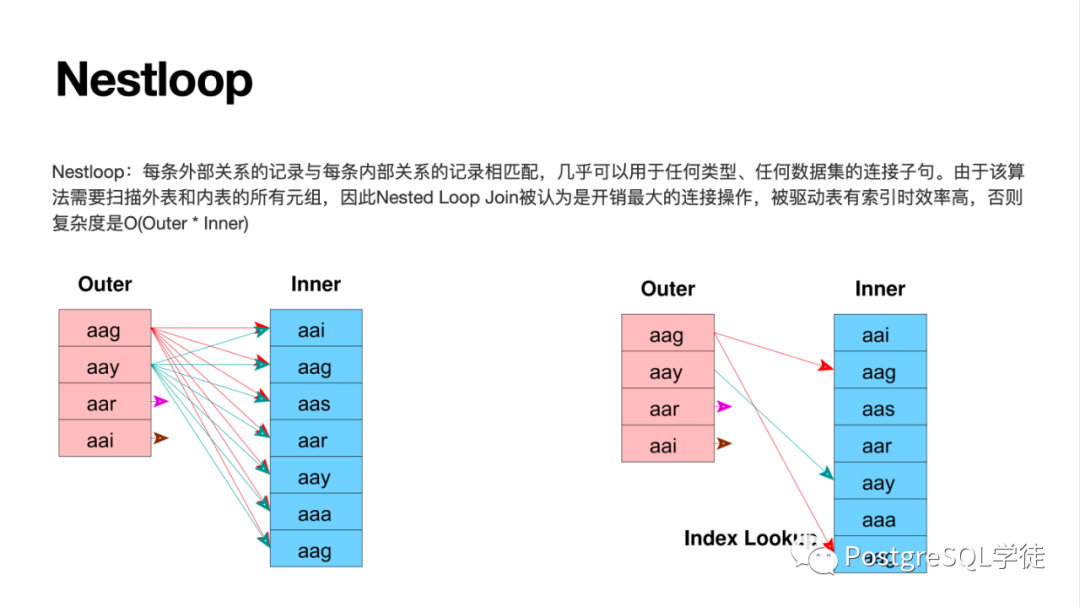
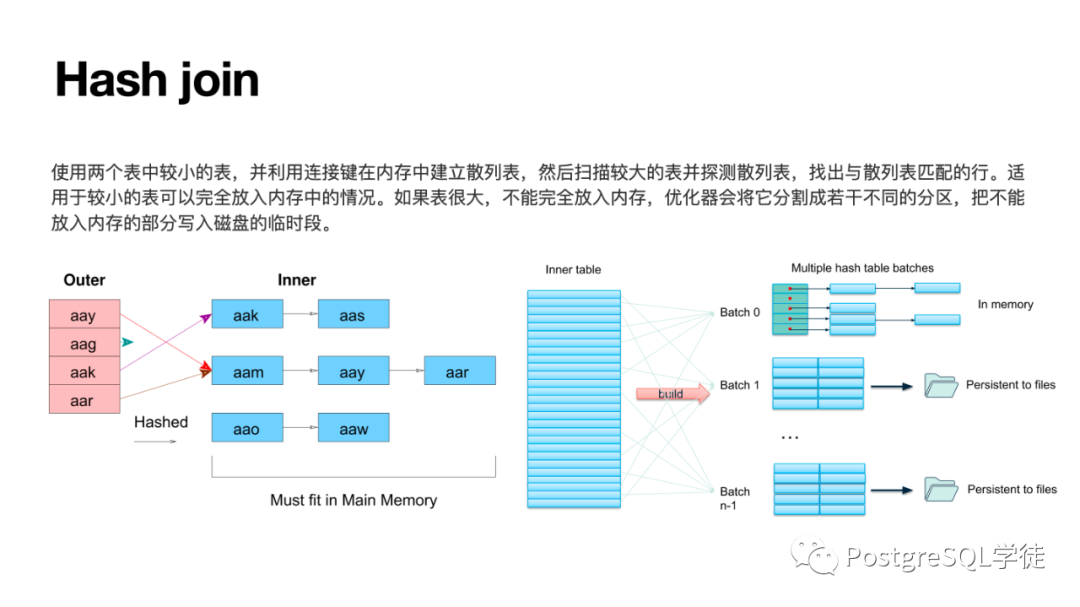
多表关联的算法包括 NSL / HASH JOIN / MERGE JOIN,HASH JOIN 要关注批次 "batch" 的问题
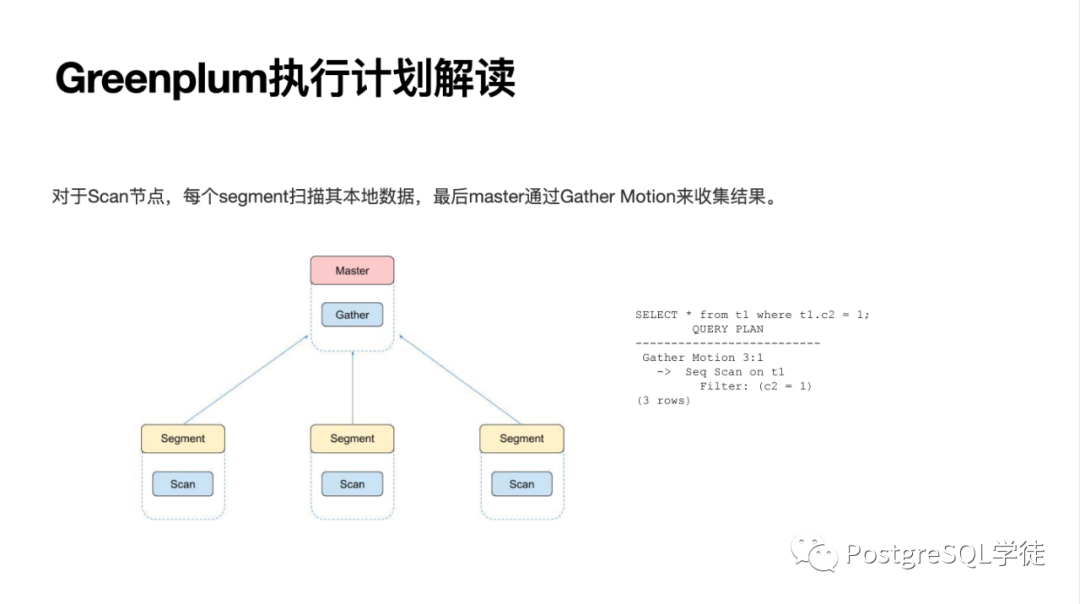
让我们回到 Greenplum,Greenplum 不同于集中式 PostgreSQL,由多个 segment + master 组成,master 仅仅是存放元信息,做结果的汇总 (Gather)
对于 JOIN,如果是基于分布键的等值连接 (因为同样的数据都位于同一个数据节点),那么每个 segment 可以本地连接,最后通过 Gather Motion 收集结果即可。
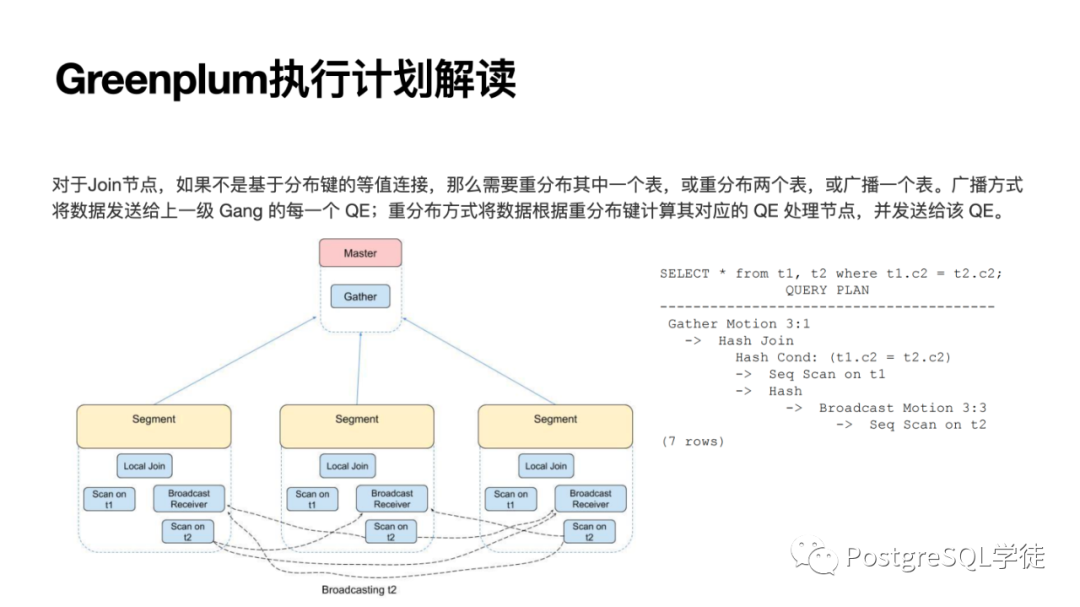
相反,如果不是基于分布键的等值连接,那么需要重分布其中一个表,或重分布两个表,或者广播,因为我需要的数据位于其他节点上了,需要将数据传输到指定节点进行关联。
比如这个计划,就很明显,没有涉及到重分布 (redistribute),而第二个由于不是分布键,就涉及到了重分布。
对于冗长的 SQL,执行计划可能满满一屏幕都看不完,人肉分析费时费力,因此我们需要借助一些工具将执行计划可视化一下,这就是 PEV,一目了然,可以迅速发现高消耗节点,着重优化这些高消耗节点,用得较多的是 "大力波"。
现在,让我们看一下实际的优化案例,老生常谈的当然是索引失效了,各位就直接看 PPT 吧。
关于分区裁剪,Greenplum7 里看着无法裁剪 stable 的函数,有环境的读者可以测一下,也欢迎读者告诉下我结果。
内存对齐我也提及过很多次,由于 CPU 取址是按照"模子" 去取的,存在着对齐。由于 Greenplum 存在行存表,AOCO 和 AORO ,此处针对传统堆表,推荐字段排放顺序如下:
一个小小的规范,可能就让你从原来需要 40C 资源,降低到了 35C,何乐而不为呢。 另外前面也提到了,SQL 是一种声明式的语言,what to do,而不是 how to do。对于一条 SQL,数据库可以有多种方式去执行,条条大路通罗马,比如顺序扫描、索引扫描,多表连接的话又有 nestloop、hashjoin、mergejoin 等,需要有一种机制告诉它如何去选择一条最优的方式去生成执行计划,这就是统计信息的作用,知道数据的一个分布情况,比如高频值,非重复值数量,是否有空值等等。 如果统计信息过旧,那么优化器做出的决策可能就不准确,我们可以根据 pg_stat_all_tables.last_analyze和last_autoanalyze 查询何时做了 analyze ,确保统计信息没有过旧。
另外就是扩展统计信息了,Greenplum7 源自 12 的内核,所以也支持
由于 Greenplum 是分布式数据库,分布键的设计至关重要,分布键的设计应遵循:数据均匀分布原则、本地操作原则和负载均衡原则。无特殊情况,不使用随机分布。
比如下面这个例子,就存在着数据倾斜,另外两个节点只能干瞪着另外一个节点热火朝天,所以木桶效应的预防尤为重要,对于所有需要设计 shard key 的数据库都是一样。
关于聚集,有两种方式:
另外 HashAggregatede 只能进行一些简单的聚合,像count (distinct …) 这类聚合是做不了的 (针对原生PostgreSQL 的情况),大部分情况下 HashAggregatede 的效率都会比 GroupAggregatede 要好,主要是排序这个操作比较耗时,本质上 GroupAggregatede 是在用空间 (内存) 换时间,内存充足的情况下这种做可以,但是内存不足容易 OOM。
另外要尤其注意 sum(bigint) 的行为,会导致每一条数据都要转换,尽量避免! 最后就是鲜为人知的 union all 了,关联的数据类型最好保持一致!否则是无法做视图展开的
可以看到这两个查询的效率天差地别,仅仅是因为数据类型的原因
小结以上便是关于 SQL 优化的一点小心得,希望各位读者阅读之后能够有所收获。 该文章在 2023/10/28 12:41:34 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886